GPT Probability Highlighter
AI, and more specifically, large language models (LLMs) are a very hot topic currently. There's ongoing debate on whether they "understand" language, or if they're just echoing text patterns they've seen during training. Regardless, they're at the point where their language generation abilities are impressive. Their performance is enough to convince me that at the very least, they "know" how to use language. In this post I want to see if I can harness their knowledge of language to build a visualiser using a small variant of GPT-2.
Goal
The aim is to create a visual tool that colours text according how likely GPT-2 thinks it is. You'll be able to enter text and see it coloured in a spectrum - green for regions that are probable, and red for less likely parts. This visualisation should offers an interesting perspective into the text's structure, and also a window into the inner workings of GPT-2.
Method
Let's start by discussing the high level overview:
- Text -> Tokens
- Tokens -> Logits
- Logits -> Highlighted Text
Text to Tokens
We start off with plain text. This text gets converted into tokens in a process called tokenisation. Tokens are what LLMs take as input. They can be thought of as the "atoms" or "building blocks" of text. They can be words, parts of a word, or symbols. Let's take a look at some text and see what the tokeniser does with it:
1from transformers import AutoModelForCausalLM, AutoTokenizer
2
3tokenizer = AutoTokenizer.from_pretrained('MBZUAI/LaMini-GPT-124M')
4tokens = tokenizer.encode("This example shows how a sentence is split into tokens.")
5for token in tokens:
6 print(tokenizer.decode(token), token)
1This 1212
2 example 1672
3 shows 2523
4 how 703
5 a 257
6 sentence 6827
7 is 318
8 split 6626
9 into 656
10 tokens 16326
11. 13
Notice how these tokens represent entire words (many of which start with a space character). This is not always the case, e.g. the tokens for "Pneumonoultramicroscopicsilicovolcanoconiosis" are:
1P 47
2neum 25668
3on 261
4oult 25955
5ram 859
6icro 2500
7sc 1416
8op 404
9ics 873
10ilic 41896
11ov 709
12ol 349
13can 5171
14ocon 36221
15iosis 42960
Tokens to Logits
Once we have our tokens, we give them to GPT-2. GPT-2 then outputs "logits" for each token. Logits are raw values indicating the likelihood of all possible subsequent tokens. Let's take a closer look:
1tokens = tokenizer.encode("This example shows how a sentence is split into tokens.", return_tensors='pt')
2model = AutoModelForCausalLM.from_pretrained('MBZUAI/LaMini-GPT-124M')
3result = model(tokens)
The result contains the "logits" for each token. Let's examine it:
1print(result.logits)
2print(result.logits.shape)
1tensor([[[-3.8851e-01, -6.1129e-02, -2.0481e+00, ..., -6.7419e+00,
2 5.4246e-03, -5.9330e+00],
3 [-1.3480e+01, -1.2948e+01, -1.4251e+01, ..., -1.9657e+01,
4 -1.1302e+01, -2.2017e+01],
5 [-1.9820e+01, -1.9594e+01, -2.3007e+01, ..., -2.6364e+01,
6 -1.9834e+01, -2.6354e+01],
7 ...,
8 [-3.1466e+01, -3.1453e+01, -3.7302e+01, ..., -3.7228e+01,
9 -3.0355e+01, -3.8497e+01],
10 [-2.2431e+01, -2.2746e+01, -2.8781e+01, ..., -3.3593e+01,
11 -2.2175e+01, -3.4478e+01],
12 [-2.0013e+01, -1.8530e+01, -1.9833e+01, ..., -2.8497e+01,
13 -7.8514e+00, -2.6733e+01]]], grad_fn=<UnsafeViewBackward0>)
14>>> print(result.logits.shape)
15torch.Size([1, 11, 50258])
We can see that the shape of the result is 1x11x50258.
The 1 is the batch size. We could've passed in many sets of token sequences, and gotten back results for each one of them. In this case we only passed in one sequence of tokens, so we only get back one batch of results.
The 11 corresponds to the number of tokens in the input sequence. We had 11, so it returns 11 50258-dimensional vectors.
The 50258-dimensional vector represents the likelihood distribution across all of the 50258 possible tokens. For example, result.logits[0, 0, 1212] indicates how likely the model thinks token 1212 is to follow after the first token in our input. Recall from above that token "1212" is "This".
We can look at what the model thinks the most likely tokens are at each stage of the input. We'll display the top three predictions at each stage:
1import torch
2top_three = torch.topk(result.logits, 3)
3
4sequence = ''
5for token, candidates in zip(tokens[0].tolist(), top_three.indices[0].tolist()):
6 sequence += tokenizer.decode(token)
7 print(f'Current sequence: "{sequence}"')
8 for n, candidate in enumerate(candidates, start=1):
9 print(f'Guess {n}: "{sequence}{tokenizer.decode(candidate)}"')
10 print()
1Current sequence: "This"
2Guess 1: "This the"
3Guess 2: "This,"
4Guess 3: "This and"
5
6Current sequence: "This example"
7Guess 1: "This example)"
8Guess 2: "This example of"
9Guess 3: "This example:"
10
11Current sequence: "This example shows"
12Guess 1: "This example shows the"
13Guess 2: "This example shows a"
14Guess 3: "This example shows that"
15
16Current sequence: "This example shows how"
17Guess 1: "This example shows how to"
18Guess 2: "This example shows how the"
19Guess 3: "This example shows how it"
20
21Current sequence: "This example shows how a"
22Guess 1: "This example shows how a person"
23Guess 2: "This example shows how a user"
24Guess 3: "This example shows how a specific"
25
26Current sequence: "This example shows how a sentence"
27Guess 1: "This example shows how a sentence can"
28Guess 2: "This example shows how a sentence is"
29Guess 3: "This example shows how a sentence structure"
30
31Current sequence: "This example shows how a sentence is"
32Guess 1: "This example shows how a sentence is structured"
33Guess 2: "This example shows how a sentence is written"
34Guess 3: "This example shows how a sentence is presented"
35
36Current sequence: "This example shows how a sentence is split"
37Guess 1: "This example shows how a sentence is split into"
38Guess 2: "This example shows how a sentence is split in"
39Guess 3: "This example shows how a sentence is split and"
40
41Current sequence: "This example shows how a sentence is split into"
42Guess 1: "This example shows how a sentence is split into two"
43Guess 2: "This example shows how a sentence is split into multiple"
44Guess 3: "This example shows how a sentence is split into three"
45
46Current sequence: "This example shows how a sentence is split into tokens"
47Guess 1: "This example shows how a sentence is split into tokens and"
48Guess 2: "This example shows how a sentence is split into tokens,"
49Guess 3: "This example shows how a sentence is split into tokens."
50
51Current sequence: "This example shows how a sentence is split into tokens."
52Guess 1: "This example shows how a sentence is split into tokens. The"
53Guess 2: "This example shows how a sentence is split into tokens.<|endoftext|>"
54Guess 3: "This example shows how a sentence is split into tokens.
55"
Now that we understand what the logits vector means, we can find a way to determine how likely a token is. We simply examine the logits vector and count the number of tokens that are less probable than the token that actually occured.
1TokenInfo = namedtuple('TokenInfo', ['token', 'ranking', 'top3'])
2
3def get_token_rankings(tokens, model, tokenizer):
4 with torch.no_grad():
5 outputs = model(tokens)
6
7 result = [
8 TokenInfo(
9 tokenizer.decode([tokens[0, i + 1]]),
10 torch.sum(outputs.logits[0, i] < outputs.logits[0, i, tokens[0, i + 1]]),
11 [tokenizer.decode(t) for t in torch.topk(outputs.logits[0, i], 3).indices]
12 ) for i in range(tokens.size(1) - 1)
13 ]
14
15 return result
Here, the token is given by:
1tokenizer.decode([tokens[0, i + 1]])
The top three predictions by:
1[tokenizer.decode(t) for t in torch.topk(outputs.logits[0, i], 3).indices]
And the ranking by:
1torch.sum(outputs.logits[0, i] < outputs.logits[0, i, tokens[0, i + 1]])
This represents a count of the number of logit values that are lower than the logit value of the observed token. It is our tally.
Sliding Input Window
The model can only take in a limited number of inputs (i.e. its context length), 512 tokens for this model. If we pass in more tokens than that, we will get an error. To avoid this problem, we can create a sliding window over the input data. We'll break the input up into windows of size 512, and shift them along by 256 tokens every time. Here's the function that takes our text and produces windows of tokens:
1def sliding_window_tokenize(text, window_size, stride, tokenizer, model):
2 text = '\n' + text
3 tokens = tokenizer.encode(text, return_tensors='pt').to(device)
4 n_tokens = tokens.size(1)
5
6 all_results = []
7 for i in range(0, n_tokens, stride):
8 window_tokens = tokens[:, i:i+window_size]
9 window_results = get_token_rankings(window_tokens, model, tokenizer)
10 all_results.extend(window_results if i == 0 else window_results[stride-1:])
11
12 return all_results
Notice that we get rid of duplicates from any new window_results. Also, a "\n" is added infront of the input. This is done because GPT cannot predict the 0th token, so we give it something to start with.
Logits to Highlighted Text
We'll create a simple GUI:
1last_text_content = ''
2last_scale = 200
3root = tk.Tk()
4root.geometry("1280x720")
5root.title('GPT Highlighter')
6root.columnconfigure(0, weight=1)
7root.rowconfigure(1, weight=1)
8
9bg_color = '#1f1f1f'
10root.configure(background=bg_color)
11
12text_widget = Text(root, fg='#acdcff', bg=bg_color, font=('Helvetica', 32))
13text_widget.grid(column=0, row=1, sticky='nsew')
14
15scale = tk.Scale(root, from_=0, to=1000)
16scale.set(last_scale)
17scale.grid(column=1, row=1, sticky='nsew')
18
19root.after(1000, highlight_text)
20
21root.mainloop()
Here, the function highlight_text is doing all the high level work. It takes the input text, finds the logits and applies a colour scheme on it:
1def highlight_text():
2 global last_text_content
3 global last_scale
4 current_text_content = text_widget.get('1.0', 'end-1c')
5 current_scale = scale.get()
6 root.after(1000, highlight_text)
7
8 if not current_text_content or (current_text_content == last_text_content and current_scale == last_scale):
9 return
10
11 for tag in text_widget.tag_names():
12 text_widget.tag_delete(tag)
13
14 last_text_content = current_text_content
15 last_scale = current_scale
16
17 window_size = 512
18 stride = 256
19 result = sliding_window_tokenize(current_text_content, window_size, stride, tokenizer, model)
20
21 line_no = 1
22 pos = 0
23 for n, entry in enumerate(result):
24 if '\n' in entry.token:
25 line_no += entry.token.count('\n') # some tokens have more than one.
26 pos = 0
27 continue
28
29 float_value = max(0, min(1, (entry.ranking - (tokenizer.vocab_size - current_scale)) / current_scale))
30 start_index = f'{line_no}.{pos}'
31 end_index = f'{line_no}.{pos + len(entry.token)}'
32 tag_name = f'Token #{n} top 3:' + ', '.join(entry.top3)
33 text_widget.tag_add(tag_name, start_index, end_index)
34 color = f'#{150 - int(float_value * 150):02X}{int(float_value * 150):02X}00'
35 text_widget.tag_config(tag_name, background=color)
36 pos += len(entry.token)
Remaining Setup
1import tkinter as tk
2import torch
3
4from collections import namedtuple
5
6from tkinter import Text
7from transformers import AutoModelForCausalLM, AutoTokenizer
8
9
10device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
11tokenizer = AutoTokenizer.from_pretrained('MBZUAI/LaMini-GPT-774M')
12model = AutoModelForCausalLM.from_pretrained('MBZUAI/LaMini-GPT-774M').to(device)
13model.eval()
Results
There are many applications for this tool. For now, I'll focus on detecting some common language errors using sample sentences and analyzing the results.
I often notice missing commas:
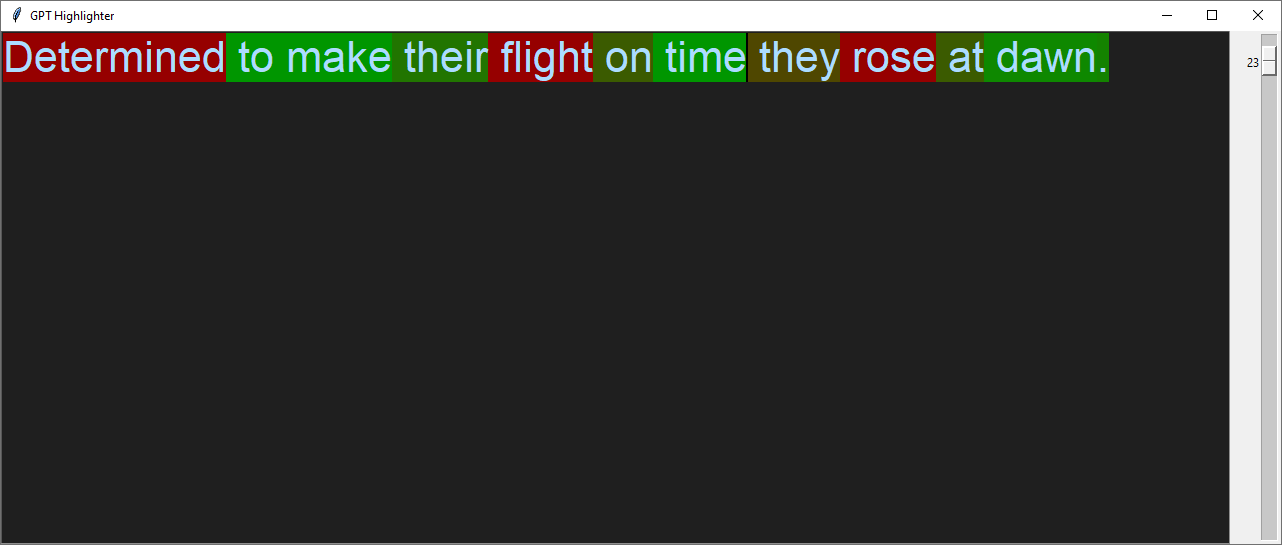
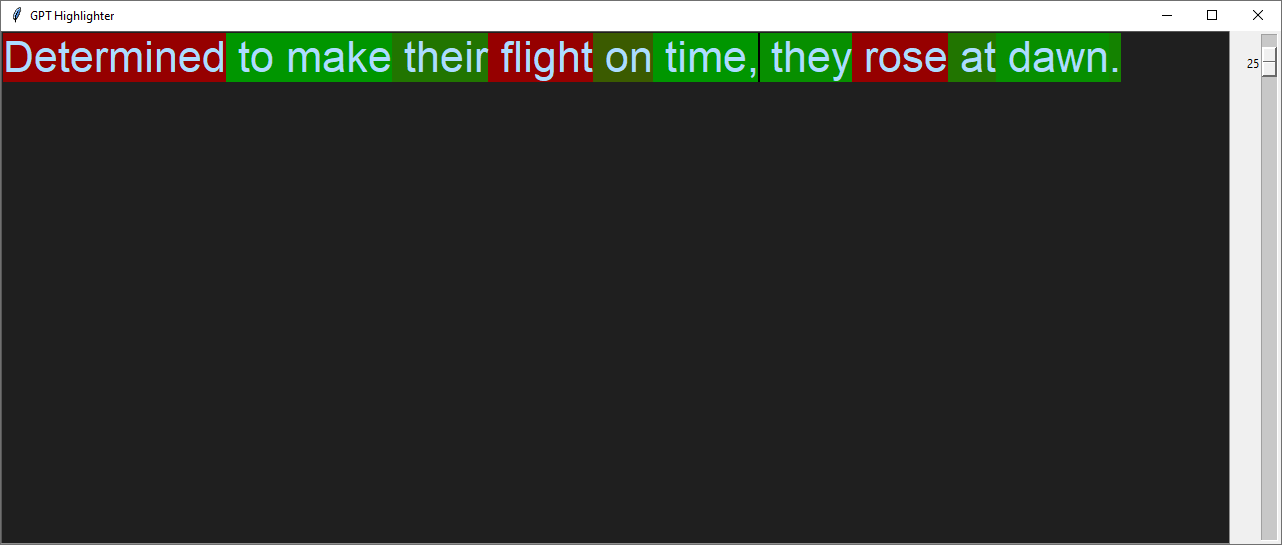
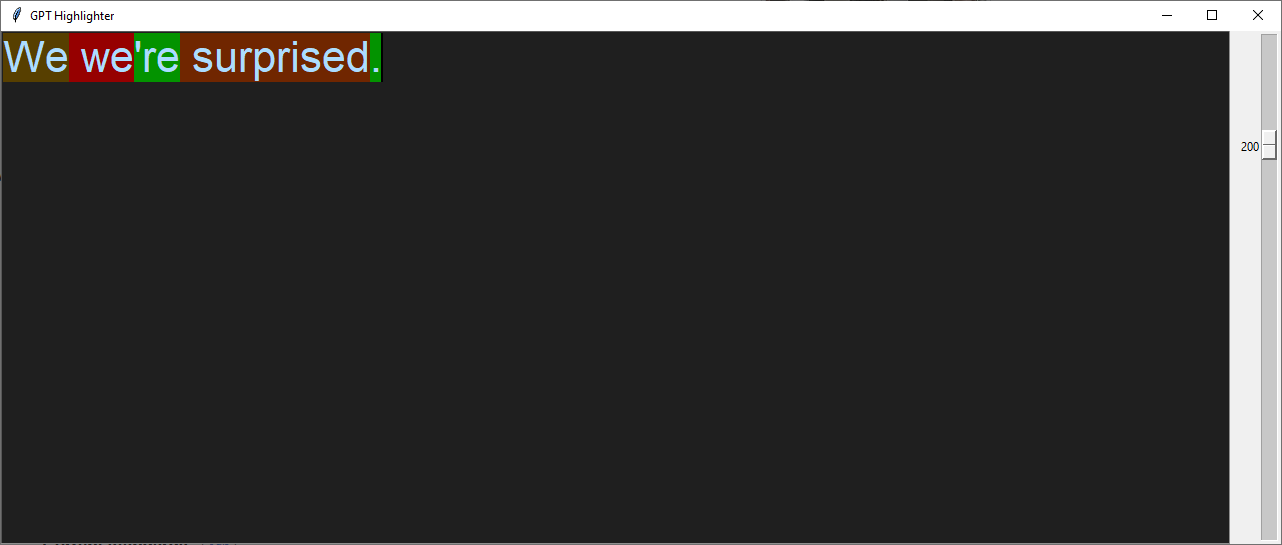
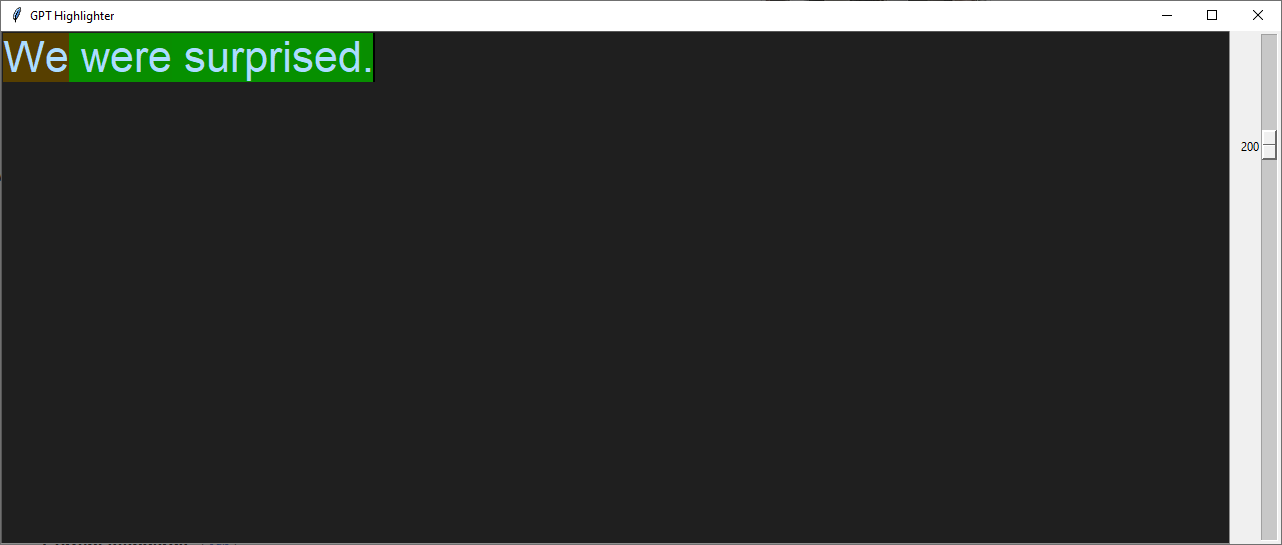
Incorrect apostrophe use is another issue:
Here are examples of various mistakes:
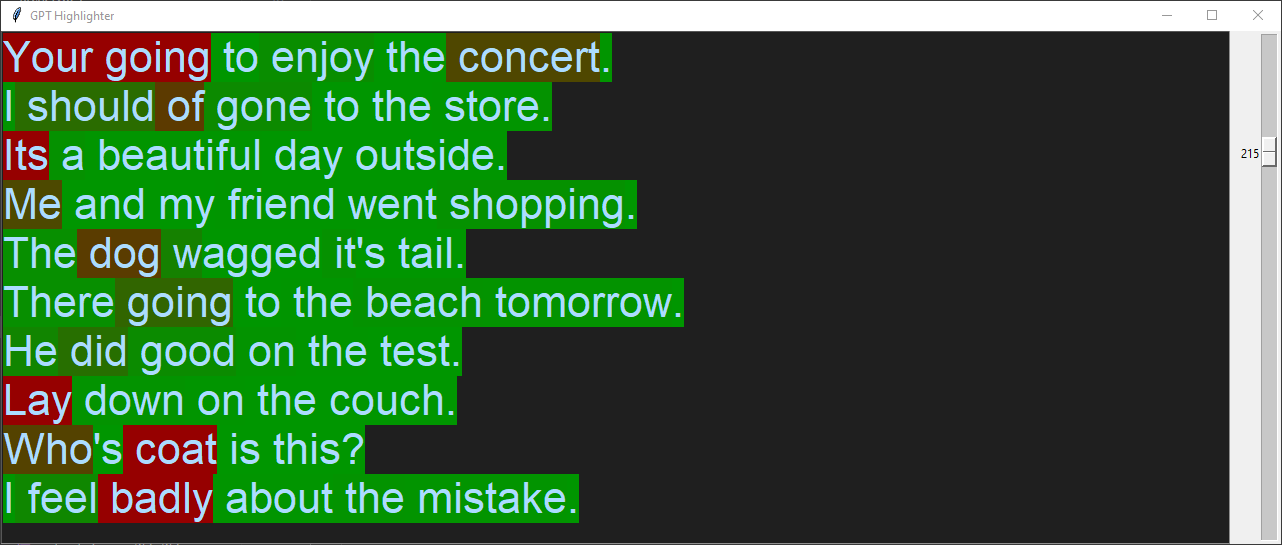

Same input, but with a lower threshold:
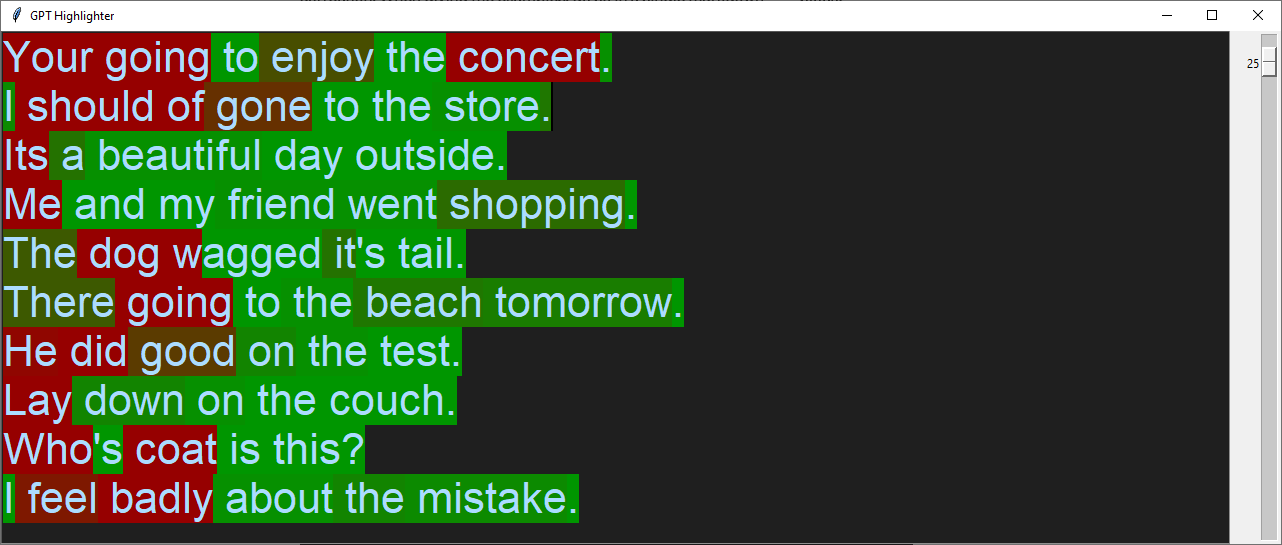

Discussion
A significant limitation of this approach is that it can only look backwards, never forwards. That explains its struggle with some of the previous examples. For instance, "The dog wagged its tail". The word "dog" fits well in this sentence, but GPT-2, just sees "The". Among the possible continuations of "The", "dog" is unlikely. Only with the additional context of "wagged its tail" does it become more probable, because now "The" must be followed by something that can wag its tail.
Other language models, such as BERT, work with full context. Unlike GPT, BERT is bidirectional (what the "B" stands for), and can look at context in both directions. However, it seems you have to run it for each token to fill in the gaps. In contrast, GPT-2 needs just one run to generate logits for all input tokens.
Conclusion
I'm quite satisfied with this tool. It has limitations, but it's excellent as a proof of concept. There are clear steps for improvement:
- Incorporating more context.
- Developing a better scheme for colouring. The current colouring, based on rank, is an alright approximation, but it might obscure information. I think a more interesting approach would be to examine the entire distribution. Things like variance should be taken into consideration.
- Adding some quality-of-life enhancements, such as automatic suggestions.